
A reference task is a certain task, which has a fixed amount of story points assigned, and which is used as a reference point to estimate other tasks. But how do you choose such a reference task? This post should give you a method and some ideas, how you can find a good reference task.
As a side node – I use the word task here for every type of work item in a sprint. So user stories, backlog items or whatever you call it – here I always use the word task.
Scales for story points
There are a couple of different scales for story points, the most common ones are the power of two (1, 2, 4, 8, 16, 32, 64, etc.) and a Fibonacci-like scale (1, 2, 3, 5, 8, 13, 20, 40, 100). (These are not really the Fibonacci numbers, but are a bit similar). It doesn´t really matter, which scale you use, the point is, that the scale shouldn´t be linear. The gaps between two numbers should become bigger the higher the numbers are. The reason is, that it is easier to say, a task is more 8 than 5 than it is to say a task is more 8 than 7. The bigger a task, the more uncertainty and therefore it is harder to distinguish little differences.
In my team we use the Fibonacci-like scale, therefore I will use that scale to explain how to choose a reference task. But before we get into that, let´s have a deeper look at the that scale.
In the Fibonacci-like scale we have nine different numbers: 1, 2, 3, 5, 8, 13, 20, 40 and 100 (sometimes you also have 0.5, but let me ignore that here). Let me call them 9 categories, because they are used to categorize the size of a task. The number 8 is in the middle of the scale. There are four categories above and four categories below 8.
We should aim to use the full scale, but – to be honest – I have never seen a team really doing that. Usually teams are only using a part of the scale, but I think you should make use of at least 6 categories (1, 2, 3, 5, 8, 13) in order to have a fine-grained differentiation of the sizes of tasks. (Basically, what I want to make clear is, that having only three categories – small, medium, large – is not enough).
I personally recommend to go for 7 or 8 categories. This should help you and your team to classify each of the given tasks in one of those categories – each category representing a certain estimated duration of effort to finish the task.
Ok, now let´s go on with the 2-step approach to find a proper reference task.
Step 1: Choose a common, medium-sized task
In step 1 you look at your tasks, which have already been finished in the past weeks and then pick one as your (temporary) reference task.
But wait, which one do I pick?
Right, that´s the question. But don´t worry, it is not so crucial to get it right in the first place. You can always change the reference task later on. Here are some guidelines, which should help you to make a good choice:
Pick a task, for which everybody in the team exactly understands, what work was required to finish it. It should be completely clear to every team member, what actions had to be done to complete the task.
It would be best if the task is a very common thing to do in your project and, in the perfect case, most of the team members have already worked on a similar task by themselves.
For example, consider following user story: “As a user I want to be able to store the birthday of customers“. This requires to add a new column in the database, adding it to the code and showing it on the front-end, maybe adding some simple validation, etc. It is probably a very common thing to do for a lot of software projects and therefore pretty clear to the team members, what actions need to be taken.
Now, let´s go to step 2, which will take you probably a couple of weeks of refinement work.
Step 2: Estimate
When you have chosen your reference task, you take the next 15-20 tasks, which you have to estimate for the upcoming sprints, and estimate each of the tasks relatively to the reference task.
What does relative estimation mean? Well, you basically decide whether the time to complete the task will be bigger, smaller or equal than the reference task.
It is a good idea to have physical cards for your tasks and put them on board. At first you place your reference task in the middle of the board. Then you estimate your first task. Your team decides it is smaller than the reference task, so you place it on the left side of the reference task. Then you estimate your second task. The team decides that it is also smaller than the reference task, but bigger than the first task – so you place the second task in the middle of the first task and the reference task.
After that your board looks like the following graph:
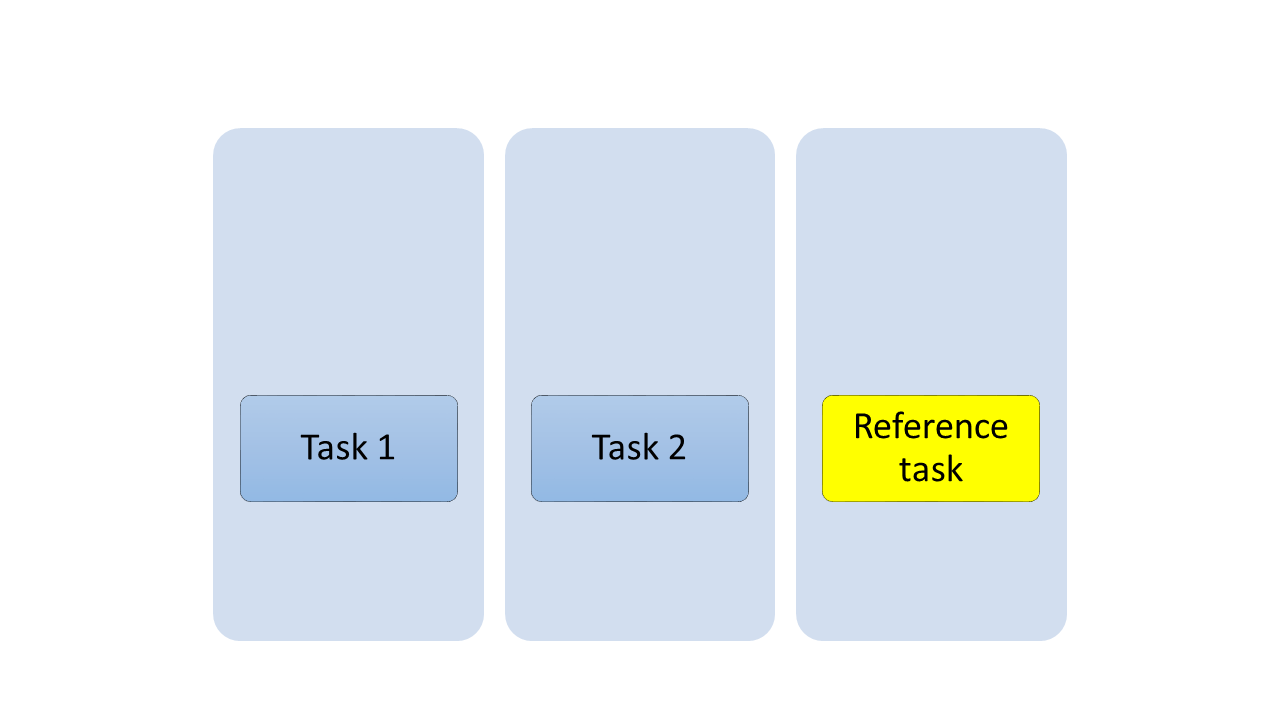
Then you continue with all the other tasks. You estimate the effort of each task relatively to the tasks which are already on the board. After a few weeks your board might look like in the next graph:
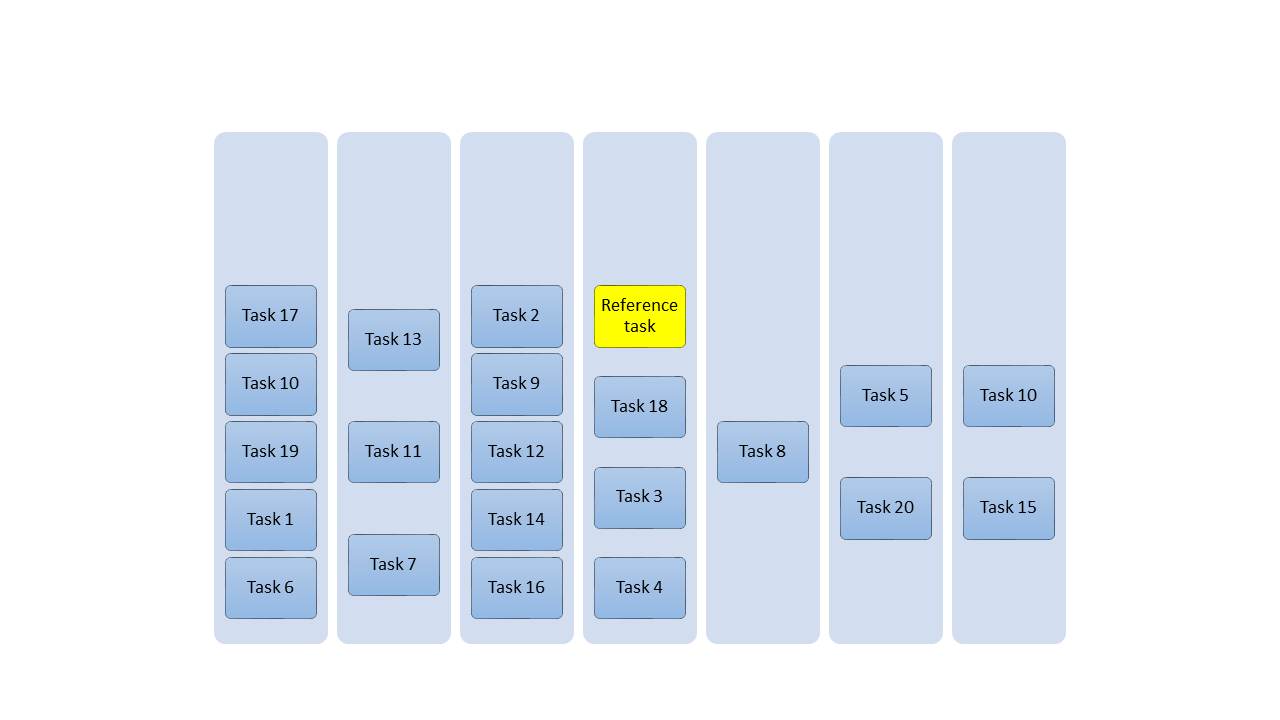
Well, probably your board won´t look like that – this would be too idealistic. The above board is more the output we want to have – in reality you probably won´t have 7 categories, but probably a bit less. And your tasks are probably also not distributed almost equally over the board as in the example above. Even your reference task might not be exactly in the middle category.
But don´t worry – that´s not a problem. The aim of this process is to find your categories and to find a proper reference task. During the creation of the board and the estimation with your team you can steer that process a bit. Before you estimate your tasks, try to pick tasks, which are very small and also tasks which are very big. This will result in more categories.
But make sure you don´t create unnecessary categories, which don´t deserve to exist by themselves. Before a new category is created, challenge the team by asking “Is the task really notable bigger than the category to the left and also notable smaller than the category to the right?” If not, you might place the task under one of the existing categories instead, and not create a new one.
Now it is also a good time to ask the question: “Was the previously selected reference task a good choice?” The reference task should be in the middle category. If this is not the case, then change your reference task and pick one task from the middle category.
Finally, when your board is in place, you assign a number of story points to each category. See here:
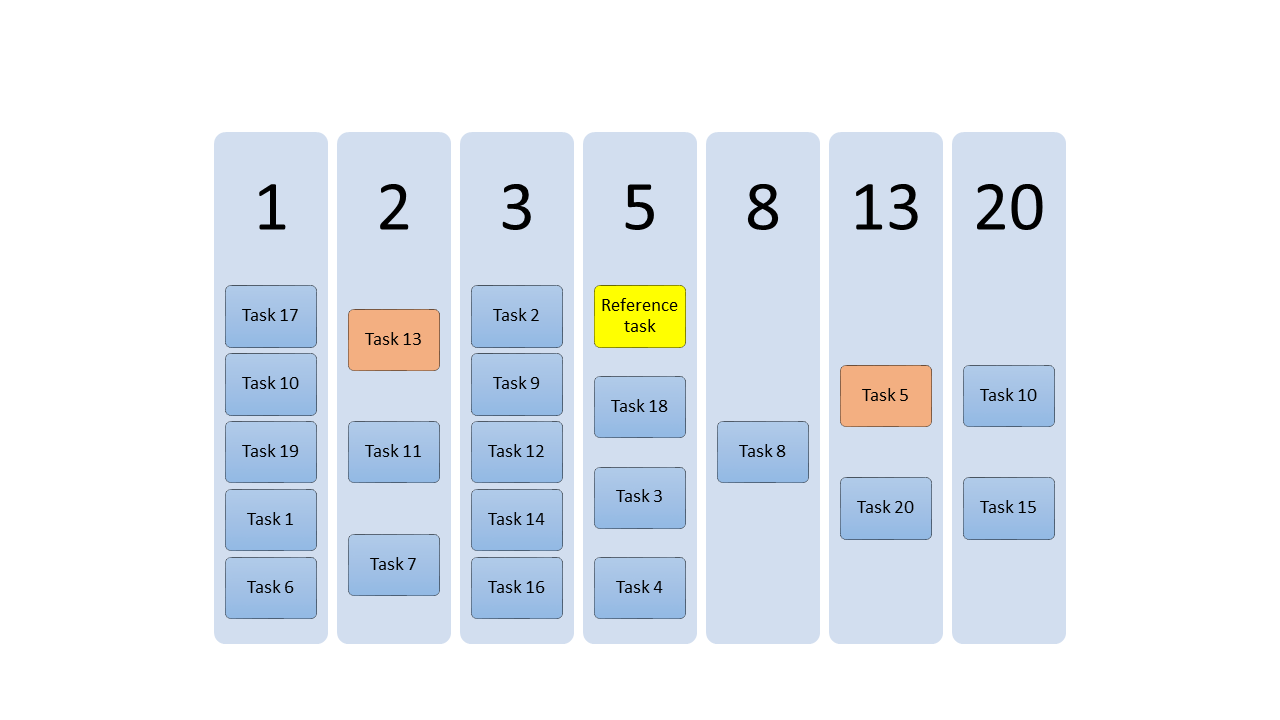
Congratulations, now you have your reference task and also the number of story points for your reference task.
Multiple reference tasks
I suggest to have not only 1 reference task, but 3 reference tasks. In the above example I picked a task from category 2 and a task from category 13 as my additional reference tasks. Having these references in place can help you and your team during estimations. Because it is easier to do estimations, when you have a reference in place.
Make your reference task visible
After a few days people in the team don´t remember anymore, what they chose for their reference tasks. But it is quite important that everybody in the team knows about the reference tasks. Because only with that they are able to do proper estimations relatively to the reference tasks. Therefore it is crucial to make them visible to the team during estimation sessions. For example, put them in your team wiki and show them on the beamer, or write them on the whiteboard, or ask a random guy in front of the group to repeat them – do something so that people remember them!
Ok, that´s it for today – leave a comment if you have anything to say! (Nice rhyme, he?)
Stay tuned and HabbediEhre!
Rather inspiring and presented in a pleasently usable way indeed‒thank you very much!
The German bit in the last line should read “habe die Ehre”. 😉
Sir, Wish to get guidance on scrum master role and PM role from you. Wish to discuss with you over skype. can you plese share your whatzapp number or skype id ?
Hi, just send me an email, then we can get in contact.
Cheers
I want to learn more from you